
{kind=link}
[ad_1]

A malicious Python package on PyPI uses Unicode as an obfuscation technique to evade detection while stealing and exfiltrating developer account credentials and other sensitive data from compromised devices.
The malicious package, codenamed “onyxproxy”, uses a combination of different Unicode fonts in the source code to help it bypass automated scans and defenses that identify potentially malicious functions based on string matching.
The discovery of onyxproxy comes from the cybersecurity specialists of Phylumwho published a report explaining the technique.
The package is no longer available on PyPI, having been removed from the platform yesterday. However, since its publication on the platform on March 15, the malicious package has amassed 183 downloads.
Unicode abused in Python
Unicode is a comprehensive character encoding standard encompassing a wide range of scripts and languages, unifying various sets/schemes under a common standard covering over 100,000 characters.
It was created to help maintain interoperability and consistent representation of text across different languages and platforms and to eliminate encoding conflicts and data corruption issues.
The “onyxproxy” package contains a “setup.py” package with thousands of suspicious code strings that use a mixture of Unicode characters.
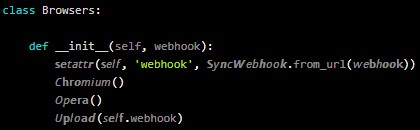
While the text of these strings, besides the different fonts, looks almost normal in visual inspections, it makes a huge difference to Python interpreters who will parse and recognize these characters as fundamentally different.
For example, Phylum explains that Unicode has five variants for the letter “n” and 19 for the letter “s” for use in different languages, math, etc. For example, the identifier “self” has 122,740 (19x19x20x17) ways of being represented in Unicode.
Python’s support for using Unicode characters for identifiers, i.e. code variables, functions, classes, modules, and other objects, allows coders to create identifiers which look identical but point to different functions.
In the case of onyxproxy, the authors used “__import__”, “subprocess”, and “CryptUnprotectData” identifiers, which are larger and have a large number of variants, easily defeating string-matching-based defenses.
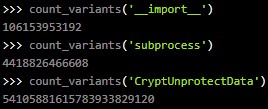
(Phylum)
Python’s support for Unicode can easily be abused to hide malicious string matches, rendering code harmless while performing malicious behavior. In this case, the theft of sensitive data and authentication tokens from developers.
While this obfuscation method isn’t particularly sophisticated, it’s concerning to see it used in the wild and could be a sign of wider Unicode abuse for Python obfuscation.
“But, whoever this author copied this obfuscated code to is smart enough to know how to use the internals of the Python interpreter to generate a new kind of obfuscated code, a kind that is somewhat readable without disclosing too much exactly what what code is trying to steal,” concludes Phylum.
The risks of Unicode in Python have been widely discussed in the Python development community in the past.
Other researchers and developers have also previously warned that Unicode support in Python will make the programming language vulnerable to a new class of security exploits, making patches and submitted code harder to inspect.
In November 2021, academic researchers presented a theoretical attack called “Trojan Sourcewhich used Unicode control characters to inject vulnerabilities into source code while making it harder for human reviewers to detect these malicious injections.
In conclusion, these attacks are now confirmed, and defenders should implement more robust detection mechanisms against these emerging threats.
[ad_2]
Source link